

前端综合笔记-JavaScript-CSS-HTML-VUE-ES6-Typescript-axios浏览器和web安全 --从入门到入坟

文章为个人整合的笔记,并无商业用途
点进来之后你的噩梦就要来了,接下来是我从业以来整理的一些基础与难点(多数来源于阅读文章与实践中遇到的问题),如果你
- 是个小白:
推荐使用2~3周的时间来消化接下来的内容,
遇到不会的没听说过名词请立刻去搜;
文章中只是简答,如果想要详细了解的话还需要你自觉去搜索 - 如果你是个大神:
好叭先给您拜个早年
请温柔点黑我。
顺便,如果有错误的地方请各位一定要指出,免得误导更多人,如果我的文章存在侵权等行为请联系我删除。
JS
基础语法操作符等
**JS数据类型分为基本数据类型与引用数据类型**--
基本数据类型有:
Number - String - Boolean - Null - Undefined - Symbol(ES6新增数据类型) - bigInt
引用数据类型统称为Object细分有:
Object - Array - Date - Function - RegExp
基本数据类型的数据直接存储在栈中;而引用数据类型的数据存储在堆中,在栈中保存数据的引用地址,这个引用地址指向的是对应的数据,以便快速查找到堆内存中的对象,如果不清楚什么是栈内存、堆内存下文会有介绍
操作符
typeof操作符
逻辑操作符 !非 可以对布尔值进行取反 布尔值取反 this.abc = ! this.abc
&&与 只要有一个值为false就返回false 如果第一个值为false 则不会继续执行
||或 两个只要有一个为true 就返回true
一个等于 = 为赋值动作 也是相同运算符用来比较两个值是否相等
两个等于 == 如果类型不同则会进行转换,转换为相同类型然后进行比较
不等于 !=
三个 === 全等用来判断两个值是否全等 ,不全等不会进行自动进行类型转换,
!== 不全等,也自动进行类型转换
三元运算符在执行时首先对条件表达式进行求值如果为true执行语句1并返回结果,如果为folse执行语句二返回结果,如果表达式的求值结果是非布尔值将其转换为布尔值然后进行运算运算符优先级 可通过()来提升优先级
for循环
for循环 for( i = 0 ; i <10 ; i ){
alert(i)
}
首先定义初始值,然后设置条件,执行语句i 返回新值 i
使用函数声明来创建一个函数:语法
function 名([形参1,形参n]){
语句
}
形参:是指形式上的参数,没有初始值
实参:是指实际上的值
实参赋值给形参:如果出现多余的实惨则不会赋值,如果出现少实惨的情况则会nan
什么是变量?
变量是那些会变化的东西(就这么简单),变量有一个值,我们能改变这个值。我们先声明一个变量名,然后对这个变量赋值,就创建了一个变量。变量分按作用域(这个很重要后面会讲到)为全局变量和局部变量。本质:变量是程序在内存中申请的一块用来存放数据的空间
什么是函数?
我们最初学习的是通过函数声明来创建一个函数,即首先是 function 关键字,然后是函数的名字,这就是指定函数名的方式。另一个方式叫做函数表达式,函数内可以读取函数外的变量,而函数外却读取不了函数内部的变量(局部变量)
数组进行扁平化
多维数组进行扁平化可使用fkat()方法
数组方法
pop 删除数组元素中的最后一个元素可多选 语法 aa.pop('123')
unshift 在数组最前面添加添加一个或多个元素 语法 aa.unshift ('123')
shift 删除数组元素中的第一个元素可多选 语法 aa.shift('123')
使用for循环遍历数组:
语法: var arr = ["孙悟空","猪八戒",“玉兔精”];
for(var i=0; i<arr.length; i ){
colog(arr[i]);
}
slice()
可以用来从数组提取指定元素
该方法不会改变元素数组,而是将截取到的元素封装到一个新数组中返回
参数: 1.截取开始的位置的索引 2.截取结束的位置的索引
var result = arr.slice(1,2); 截取arr中的第二个和第三个字段
push 在数组尾部添加一个或多个元素 语法 aa.push('123')
splice()
可以用于删除数组中的指定元素
使用splice()会影响到原数组,会将指定元素从原数组中删除
并将被删除的元素作为返回值返回
参数: 第一个表示开始位置的索引 第二个表示删除的数量 第三个参数以及以后 可以传递新元素可以插入到开始元素前面
语法: var result = arr.splice(0,1,"牛魔王") 删中arr中的第第一个元素删除一天,并天元素牛魔王
concat()
可以连接两个或多个数组,并将新的得数组返回 ,该方法不会对原数组产生影响
语法 var result = arr.concat(arr2,arr3,"大帅比");
将数组arr2 arr3 元素大帅比 添加到 arr中
join()
该方法可以将数组转换为一个字符串
该方法不会对原数组产生影响,而是将转换后的字符串作为结果返回
在join()中可以指定一个字符串作为参数,这个字符串会成为数组元素的连接符
如果不指定,默认为,
语法: var result =arr.json(“”)
reverse()
该方法用来翻转数组(前面的到后面去,后面的到前面去)该方法会直接修改原数组
语法 arr.reverse();
sort
可以用来对数组的元素进行排序
也会影响原数组,默认按照unicode编码排序
arr.sort()
即使对于纯数字的数组,使用sort()排序时,也会按照unicode来排序
所以对数字进行排序时,可能会得到错误结果
我们自己指定排序规则
arguments
在调用函数时,浏览器每次都会传递两个隐含的参数
函数的上下文对象this
封装实惨的对象arguments
arguments是一个类数组对象,它可以通过索引来操作数据,也可以获取长度
在调用函数时,我们所传递的实参都会在arguments中保存
arguments.length可以用来获取实参的长度
我们即使不定义形参,也可以通过arguments来使用实参
只不过比较麻烦
arguments【0】 表示第一个实参
它里面有一个属性叫做callee
这个属性对应一个函数对象,就是当前正在指向函数的对象
语法: 获取实参的长度 获取实参的属性值
function fun(){ function fun() {
clog(arguments.length) clog(arguments[0])
} }
Math
.ceil() 可以对一个数进行向上取整,小数位只要有值就会自动进1
.foor 可以对一个数进行向下取整。小数部分会被割掉
.round 可以对一个数进行四舍五入
.random 可以用来生成0-1之间的随机数
.max 取最大值
min 取最小值
forEach() 需要一个函数作为参数
像这种函数,由我们创建不是由我们调用,我们成为回调函数
会遍历数组里所有的元素
以实参形式传入,
浏览器在回调函数中传递三个参数
第一个参数,就是当前正在遍历的元素
第二个参数,就是正在遍历的元素索引
第三个参数,就是正在遍历的数组
arr.forEach(function(value,index,obj){
clog(value)
})
字符串的方法
JS字符串截取
1.通过单一字符将字符串切割成多字符
var data= "外面在下雨,天气真冷,你现在到哪里了呀,我们待会一起吃饭吧。";
var str = data.split(',');
结果:
str[0] =外面在下雨
str[1] =天气真冷
str[2] =你现在到哪里了呀
str[3] =我们待会一起吃饭吧。
2.通过多字符将字符串切割成多字符串
var data= "外面在下雨,天气真冷,你现在到哪里了呀,我们待会一起吃饭吧。";
var str = data.split(/在,/);
结果:
str[0] =外面
str[1] =下雨
str[2] =天气真冷
str[3] =你现
str[4] =到哪里了呀
str[5] =我们待会一起吃饭吧。
charAt() 返回指定索引位置的字符
concat() 接两个或多个字符串,返回连接后的字符串
indexOf() 返回字符串中检索指定字符第一次出现的位置,可以有两个参数,指定开始查找的位置,从前往后找
lastIndexOf() 返回字符串中检索指定字符最后一次出现的位置,从后往前找
slie()可以从字符串中截取指定的内容,不会影响原数组,会返回
参数:第一个 开始位置 第二个结束的位置
split 可以截取字符串拆分为一个数组
toLowerCase() 把字符串转换为小写
正则表达式
[]里面的内容也是或的关系
[a-z]任意小写字母 [A-z]任意字母
^ 除了 如 [^AB] 找除了AB以外的东西
修饰符:
i 执行对大小写不进行区分
g 进行全局匹配(正常查找所有是在找到第一个停止)
m 执行多行匹配
表达式:
abc] 查找方括号之间的任何字符。[0-9] 查找任何从 0 至 9 的数字。
(x|y) 查找任何以 | 分隔的选项。
元字符:
\d 查找数字 \s 查找空白字符。
量词:
n 匹配任何包含至少一个 n 的字符串
n* 匹配任何包含零个或多个 n 的字符串。
n? 匹配任何包含零个或一个 n 的字符串。
RegExp 对象
RegExp 对象是一个预定义了属性和方法的正则表达式对象。
test() 方法是一个正则表达式方法。方法用于检测一个字符串是否匹配某个模式,如果字符串中含有匹配的文本,则返回 true,否则返回 false。
exec() 方法是一个正则表达式方法。exec() 方法用于检索字符串中的正则表达式的匹配。该函数返回一个数组,其中存放匹配的结果。如果未找到匹配,则返回值为 null。
Switch…case语句
在执行时依次将case后的值和swich的后条件表达式进行比较,进行全等操作如果为true开始进行代码如果为false则往下执行,break关键字跳出程序·,如果结果都为false则执行default后的语句
作用域:
作用域是指一个变量的作用域范围
全局作用域在页面打开时创建,在页面关闭时销毁
在全局作用域中只有一个全局对象window
他代表是一个浏览器的窗口,他由浏览器创造可以直接使用
在全局作用域中:
创建的变量会作为window对象的属性保存
创建的函数都会为window对象的方法保存
在全局作用域的变量都是全局变量
在页面任何部分都可以访问到
this:
解析器在调用函数每次都会向内部传递一个隐含的参数
这个隐含的参数this , this指向的是一个对象
这个对象称为方式的不同, this会指向不同的对象
1. 以函数的形式调用是, this 永远都为window
2. 以方法调用时,this就是永远都是调用方法那个对象
什么是原型链
在学习原型链之前,先了解三个基本概念:***构造函数,实例对象,原型对象***
构造函数
构造函数也是一个函数,只不过它比普通函数多一个功能,使用new关键字调用时能创建对象.
function student(){
this.name = "张三";
}
var stu1 = new student(); //创建对象
console.log(stu1.name); //输出张三
上面定义的student函数就是一个构造函数,通过使用new关键字生成一个新对象
实例对象
实例对象是使用new关键字调用构造函数后返回的新对象.对应到上面代码中的stu1
原型对象:
我们所创建的每一个函数,解析器都会向函数添加一个属性protottype
这个属性对应着一个对象,这个对象就是我们的原型对象
如果函数作为普通的prototype没有任何作用
当函数以构造的形式调用时,它创建的对象中都会有一个隐含的属性
指向该构造函数的原型对象,我们可以通过 --proto--来访问
语法:
比如我要查看 mc的原型 clog (mc.--proto--); 看mc原型的原型 clog (mc.--proto--.--proto--);
指向该构造函数的原型对象,我们可以通过--proto--来访问该属性
原型对就相当于一个公共区域,所有的同一个类的实例都可以访问到这个原型对象
我们可以将对象中共有的内容,统一设置到原型对象中
当我们访问对象一个属性方法是,他会先在对象自身中寻找,如果有则直接使用
如果没有则回去原型中寻找,如果找到直接用
创建构造函数中将对象共有的属性和方法统一添加到构造函数的原型对象中
这样不用分别为每一个对象添加,也不会影响到全局作用域
语法:
var mc = new Myclass(); 在mc中添加实例Myclass
myclass.prototype.a = 123; 向myclass中的原型对象添加属性a值是23
in 使用in 可以检测对象中是否有该属性 如果原型对象中有也返回true
语法: clog (“name” in mc)检查mc中是否拥有name属性
hasOwnProperty() 使用该方法来检查对象中自身中是否含有该属性
使用方法中只有当前对象中含有属性时才会返回true
语法: clog (ma.hasOwnProperty (“age”))检查ma中是否拥有age属性
原型对象也有对象,所以它也有原型
当我们使用一个对象的属性或方法时,会先在自身中寻找
自身如果有,则直接使用
如果没有则去原型对象中寻找,如果原型对象有与则使用
如果没有择取原型对的原型里寻找,直到到object对象的原型
object对象的原型没有原型,如果在onject中依然没有找到,则返回undefined
原型链:就是实例对象和原型对象之间的链接,每一个对象都有原型,原型本身又是对象,原型又有原型,以此类推形成一个链式结构.称为原型链
instanceof原理实际上就是查找目标对象的原型链
包装类
js中为我们提供了三个包装类,通过三个包装类可以将基本数据类型转换为对象
String() 可以将基本数据类型字符串转为String类型
Number() 可以将基本数据类型的数字转为Number对象
Boolean() 可以将基本数据布尔值转为Boolean对象
方法和属性只能添加给对象,不能添加给基本数据类型
当我们对一些基本数据类型的值去调用属性和方法时
浏览器会临时包装类将其转换为对象,然后在调用对象的属性和方法
调用完以后,在将其转为基本数据类型
JSON
数组(Array)用方括号表示("[]")表示
对象(Object)用大括号表示(“{}”)表示
名称/值对(name/value)之间用冒号(“:”) 隔开
名称(name)置于双引号中,值(value)有字符串、数值、布尔值、null、对象和数组
并列的数据直接用逗号(“,”)分割
1.对象(object)
对象用大括号(“{}”)括起来,大括号里一系列的“名称、值对”
2.数组(Array)
数组表示一系列有序的值,用【】包围起来用,分割
3.名称、值对(name、value)
名称(Name) 是一个字符串,要用双引号括起来,不能用单引号,值得类型有七种:字符串(string)、数值(number)、对象(object)、数组(array)、true、false、null、不能有这之外得类型,类如undefined,函数等。
字符串(string)
英文双引号括起来,,字符串中不能单独出现双引号,和又斜杠(“\”),如果要使用需要可以使用转义符
解析JSON字符串的方法
使用eval()不推荐使用
使用json.parse()
parse,可以有两个参数,第一个是函数,此函数有两个参数:name和value 分别代表名称和值,当代入一个json字符串后,json的每一组名称、值都要调用此函数,该函数有返回值,返回值将赋值给当前名称name
第二个参数,可以在解析json字符串的同时,对数据进行一些处理
闭包
什么才能称得上闭包?
闭包需要满足四个条件
1.有函数函数嵌套
2.内部函数引用外部作用域的变量参数
3.返回值是函数
4.创建一个对象函数,让其长期驻留
用完可以释放掉,不用担心内存
为什么要使用闭包?
因为全局变量容易污染环境,而局部变量又无法长期驻留内存,于是我们需要
一种机制,既能长期保存变量又不污染全局,这就是闭包。
DOM
Dom 全称Document Object Model 文档对象模型
JS中通过DOM来操作HTML文档进行操作,只要理解了dom就可以随意操作WEB页面
·文档:文档表示的就是整个HTML页面文档
·对象:对象表示网页中每一个部分都转为了一个对象
·模型:使用模型来表示对象之间的关系,这样方便我们获取对象
文档节点:整个HTML文档
元素节点:html文档中的标签 如h1
属性节点:元素的属性 如id
文本节点:html标签中的文本内容 如<、h1>我是文本节点<、h1>
事件onload
js中事件onload事件,整个页面加载完成之后才能触发
为window绑定一个onload事件
该事件对应的响应函数将会在页面加载完成之后执行
window.onload =function(){
}
获得元素节点 通过document对象调用
getElmentById() 通过id获取一个元素节点对象
getElementsByTagName() 通过标签名获取一组元素节点对象
getElementsByName() 通过name属性获取一组节点对象
getElementsByTagName() 方法,返回当前节点的指定标签名节点
childNodes -属性,表达当前节点的所有子节点
firstChild 属性,表示当前节点的第一个子节点
lastChild属性 , 表示当前的最后一个子节点
js鼠标事件
1 onclick — 鼠标点击执行js函数
2 onfocus — 光标选中执行js函数
3 onblur — 光标移走执行js函数
4 onmouSEO((Search Engine Optimization))ver — 鼠标移到某个标签执行js函数
5 onmouSEO((Search Engine Optimization))ut — 鼠标从某个标签移走执行js函数
js键盘事件
1.keydown:在键盘上按下某个键时触发。
2.keypress:按下某个键盘键并释放时触发
3.keyup:释放某个键盘键时触发
什么是同步什么是异步?
同步 是指按照从上到下的顺序一步一步执行,举个例子
clog('我是第一件事');
clog('我是第二件事');
for(var i = 0; i < 10; i ){
clog(‘我是第三件事’)
}
clog('我是第四件事');
同步是要等上面全部执行完才会执行下面
异步
异步就是主程序继续走,延迟和等待程序挂到另外一个列表中等待执行,不阻塞js中大部分都是同步,少有异步有如下几个:定时器settimeou和setlterval,ajax的异步请求/promise;
异步的好处就是不会因延时和等待阻塞程序
都是异步也有自身的问题存在
什么是深/浅拷贝?,有哪些实现方式
基本数据类型:string、number、boolean、undefined、null
引用数据类型:object、array、function
JS数据类型分为基本数据类型和引用数据类型,基本数据类型保存的是值,引用类型保存的是引用地址(this指针)。浅拷贝共用一个引用地址,深拷贝会创建新的内存地址。
Object.assign:对象的合并 (第一级属性深拷贝,第一级以下的级别属性浅拷贝。)
ES6中的 Object.assign(),第一个参数必须是个空对象。
Object.assign() 方法可以把任意多个的源对象自身的可枚举属性拷贝给目标对象,然后返回目标对象。
Promise.all和Promise.race的区别,应用场景
Promise.all()可以将多个实例组装个成一个新实例,成功的时候返回一个成功的数组;失败的时候则返回最先被reject失败状态的值。
适用场景:比如当一个页面需要在很多个模块的数据都返回回来时才正常显示,否则loading。
promise.all中的子任务是并发执行的,适用于前后没有依赖关系的。Promise.race()意为赛跑的意思,也就是数组中的任务哪个获取的块,就返回哪个,不管结果本身是成功还是失败。一般用于和定时器绑定,比如将一个请求和三秒的定时器包装成Promise实例,加入到Promise队列中,请求三秒中还没有回应时,给用户一些提示或相应的操作。
微任务和宏任务的区
1.宏任务:当前调用栈中执行的代码成为宏任务。(主代码快,定时器等等)。
2.微任务: 当前(此次事件循环中)宏任务执行完,在下一个宏任务开始之前需要执行的任务,可以理解为回调事件。(promise.then,proness.nextTick等等)。
3. 宏任务中的事件放在callback queue中,由事件触发线程维护;微任务的事件放在微任务队列中,由js引擎线程维护。
微任务:process.nextTick、MutationObserver、Promise.then catch finally
宏任务:I/O、setTimeout、setInterval、setImmediate、requestAnimationFrame
什么是栈内存和堆内存?
原文地址
在js引擎中对变量的存储主要有两个位置,堆内存和栈内存。栈内存主要用于存储各种基本类型的变量,包括Boolean、Number、String、Undefined、Null,以及对象变量的指针(地址值)。栈内存中的变量一般都是已知大小或者有范围上限的,算作一种简单存储。而堆内存主要负责像对象Object这种变量类型的存储,对于大小这方面,一般都是未知的。
栈内存:
栈是一种先进后出的数据结构,栈内存是内存中用于存放临时变量的一片内存块。它是一种特殊的列表,栈内的元素只能通过列表的一端访问,这一端称为栈顶,另一端称为栈底,存储数据一般来说,栈内存主要用于存储各种基本类型的变量,包括Boolean、Number、String、Undefined、Null…以及对象变量的指针。
为方便理解 这里我们通过类比乒乓球盒子来分析栈的存取方式
这种乒乓球的存放方式与栈中存取数据的方式如出一辙。 处于顶层的乒乓球5号,它一定是最后被放进去的,但可以最先被拿来使用。 而我们想要使用底层的乒乓球1号,就必须将上面的 4 个乒乓球取出来,让乒乓球1号处于盒子顶层。 这就是栈空间先进后出,后进先出的特点。
堆内存
堆内存的存储不同于栈,虽然他们都是内存中的一片空间,但是堆内存存储变量时没有什么规律可言。它只会用一块足够大的空间来存储变量,堆内存主要负责像对象Object这种变量类型的存储,堆内存存储的对象类型数据对于大小这方面,一般都是未知的,(这大概也是为什么null作为一个object类型的变量却存储在栈内存中的原因)
因此当我们要访问堆内存中的引用数据类型时,实际上我们首先是从变量中获取了该对象的地址指针, 然后再从堆内存中取得我们需要的数据。
let a = 20;
let b = a;
b = 30;
console.log(a); // 此时a的值是多少,是30?还是20?
在这个例子中,a、b 都是基本类型,它们的值是存储在栈内存中的,a、b 分别有各自独立的栈空间,
所以修改了 b 的值以后,a 的值并不会发生变化。
四.栈内存和堆内存的优缺点
1.在JS中,基本数据类型变量大小固定,并且操作简单容易,所以把它们放入栈中存储。 引用类型变量大小不固定,所以把它们分配给堆中,让他们申请空间的时候自己确定大小,这样把它们分开存储能够使得程序运行起来占用的内存最小。
2.栈内存由于它的特点,所以它的系统效率较高。 堆内存需要分配空间和地址,还要把地址存到栈中,所以效率低于栈。
五.栈内存和堆内存的垃圾回收:
1.栈内存中变量一般在它的当前执行环境结束就会被销毁被垃圾回收制回收, 而堆内存中的变量则不会,因为不确定其他的地方是不是还有一些对它的引用。 堆内存中的变量只有在所有对它的引用都结束的时候才会被回收。
对象中加入新值 var list = {stNum: “0003”,stdGroup: “12”}
(1). var key = ‘isSelects’
var value = true
list[key] = value
结果 {stNum: “0003”,stdGroup: “12”,isSelects:true}
TS
TS中的类型
any
any 表示的是任意类型,一个变量设置类型为 any 后相当于对该变量 关闭了TS的类型检测; ***使用TS 的时,不建议使用any类型, 例:let d:ang;❌不建议; 声明变量如果不指定类型,则TS 解析器会自动判断变量的类型为
any,(隐式的any) let d; d = 10; //d 的隐式类型为any
unknow
unknow 实际上就是一个类型安全的any类型; unknow 类型的变量,不能直接赋值给其他变量;
any类型会影响其他变量类型的规定,未知变量类型是使用unknow; 例: let e: unknow; e = 10; e =
‘hello’; e = true; 如果需要变量赋值,可以使用 if 来判断是否是此类型,进而赋值 if(typeof e ===
‘string’){
s = e } 类型断言,可以用来告诉解析器变量的实际类型 /* 语法:
变量 as 类型;
<类型>变量
*/ s = e as string; s = e;
void 用来表示空,以函数为例,就是表示没有返回值的函数 function fn(): void{ } never
表示永远不会返回结果 function fn2(): never{
throw new Error(‘报错了’); }
设置函数结构的类型声明:
语法:(形参:类型,形参:类型…) => 返回值 let d:(a: number,b: number) => number;
//指定义一个类型,参数类型都为number,函数返回值也是number; 例:相当于;
d = function (n1: string,n2: string): number{
return 10;
}
元组,元组就是固定长度的数组
语法:[类型,类型,类型...] 例: let h: [string,number]; h = ['hello',123];
enum 枚举类型定义
// 定义枚举类型 enum Gender{
Male,
Female } let i: {name: string,gender: Gender}; i = {
name: ‘孙悟空’,
gender:Gender.Male // ‘male’ } console.log(i.gender === Gender.Male); //true
type myType = 1 | 2 | 3 | 4 | 5; // | 或的意思 let k: myType; let l:
myType; let m: myType; // 此时,k、l、m可以且必须是1-5的值;
class 类的定义
什么是面向对象?
简单来说就是万物皆是对象
class 类名
使用class来定义一个类
//对象中包含两个部分 属性 方法
// class person {
// //定义实例属性 直接写的为实例需要配合对象去调用
// readonly name: string = '孙悟空';//readonly 表示只读属性
// static age: number = 18; //在属性前使用static关键字可以定义类属性(静态)
// static hello(){//定义方法
// console.log('123321');
// }
// }
// const per = new person(); //实例化一个类
// console.log(per.name); //指接定义的属性是实例属性,需要通过对象的实例去访问
// console.log(person.age); //使用static静态属性(也叫类属性)可以直接访问
// person.hello(); //调用类方法
构造函数
class Dog {
// name: string;
// age: number;
// constructor 被称为构造函数
// 构造函数会在对象创建时调用
constructor(name: string,age: number) { //构造函数传参
// console.log('构造函数执行了'); //调用new函数就相当于调用构造函数constructor
// 在实例方法中,this就表示当前的实例
// 在构造函数中当前对象就是当前新建的那个对象
// 所以,可以通过this向新建的对象中添加属性;
this.name = name;
this.age = age;
// console.log('this',this); // Dog {}
}
bark(){
alert('汪汪汪')
}
}
const dog1 = new Dog('小黑',3); //调用new函数就相当于调用构造函数constructor
const dog2 = new Dog('小白',5);
console.log(dog1);
console.log(dog2);
继承
// class Dog {
// name: string;
// age: number;
// constructor(name: string, age: number) {
// this.name = name;
// this.age = age
// }
// dark() {
// console.log('狗在叫');
// }
// }
// class sommDog extends Dog{ //使sommDog继承Dog类 此时Dog为父类 sommDog为子类 使用后子类将继承父所有方法以及属性
// run(){
// console.log(this.name '在跑'); //子类拥有自己的方法
// }
// dark() { //如果子类和父类的方法相同 子类会覆盖父类的方法
// console.log('狗在叫');
// }
// }
// const sommmdogs = new sommDog('狗',2)
// console.log(sommmdogs);
// sommmdogs.dark();
// sommmdogs.run();
//已abstract开头的类 是抽象类与普通类不同的是不能创建对象
//抽象类就是专门给别人继承的类 ,(创建下来就是当爸爸的)
// abstract class Dog {
// name: string;
// age: number;
// constructor(name: string, age: number) {
// this.name = name;
// this.age = age
// }
// //定义一个抽象方法,抽象反法使用abstract开头没有方法体,抽象方法只能定义在抽象类中,子类必须对抽象方法进行重写
// abstract dark(): void //void表示没有返回值
// }
// class sommDog extends Dog { //使sommDog继承Dog类 此时Dog为父类 sommDog为子类 使用后子类将继承父所有方法以及属性
// // age: number;
// // constructor(name: string, age: number) {
// // super(name, age); //super在类的方法中 super就表示当前类的父类 如果子类中写了构造函数,在子类构造函数中必须对父类进行调用
// // this.age = age;
// // }
// dark(){
// }
// }
// const sommmdogs = new sommDog('狗', 2)
// console.log(sommmdogs);
// sommmdogs.dark();
接口
(() => {
// 什么是接口
// console.log('接口');
/*
TS中的接口其实就是指约定一个对象的类型;
定义接口有两种方式:
① 使用 type 方式
② 使用interface 方式
*/
//① type 描述一个对象的类型
type myType = {
name: string,
age: number,
}
/** ① interface 接口形式描述一个对象的类型
* 接口用来定义一个类结构,用来定义一个类中应该包含哪些属性和方法
* 同时接口也可以当成类型声明去使用
* 接口可以重复名字,重复名字定义的接口字段属性会叠加;
*/
interface myInterface{
name: string,
age: number,
}
interface myInterface{
sex:'男'
}
/** type & interface二者区别
* 接口可以在定义类的时候去限制类的接口,
* 接口中的所有属性都不能有实际的值,
* 接口只定义对象的结构,而不考虑实际的值
* 在接口中,所有的方法都是抽象方法;
*/
interface myInter{
// 都是抽象的
name: string;
sayHello():void;
}
/**
* 定义类时,可以使类去实现一个接口
* 实现接口就是使类满足接口的要求
* 使用implements关键字来实现接口继承
*/
// 什么叫接口,只要有看这个接口之后,才可以正常的数据通信;
// 实际接口就是对我们这个类的限制,制定规范,规定类型;
class myClass implements myInter{
name: string;
constructor(name: string){
this.name = name;
}
sayHello(): void {
console.log('大家好');
}
}
const obj: myInterface = {
name:'jack',
age:12,
sex:'男'
}
console.log(obj);
})();
TS 中属性的封装
属性的封装,目的就是让类中的属性访问时更加安全,不能直接修改需要通过类中提供的get和set方法来读取和修改;
public 指修饰的属性可以在任意位置访问和(修改) 是默认值
private 私有属性,私有属性只能在类内部访问(修改)
protected 受保护的属性,只能在当前类和当前类的子类中使用
(() => {
// 属性的封装
// 定义一个人的类
class Person{
// TS 可以在属性前添加属性的修饰符,来限制属性的访问以及修改
/**
* public 指修饰的属性可以在任意位置访问和(修改) 是默认值
* private 私有属性,私有属性只能在类内部访问(修改)
* ---通过在类中添加方法,使得私有属性可以被外部访问
* protected 受保护的属性,只能在当前类和当前类的子类中使用
*/
private _name: string;
private _age: number;
constructor(name: string,age: number){
this._name = name;
this._age = age;
}
/* 第二种方法,使用类中自带的属性存取器来设置访问和修改属性的方法
getter 方法用来读取属性
setter 方法用来设置属性
------- 它们被称为属性的存取器
*/
// TS 中设置getter方法的方式
get name(){
console.log('get name()执行了');
return this._name
}
// TS 中设置setter方法的方式
set name(value: string){
// console.log('set name()执行了');
this._name = value;
}
get age(){
return this._age
}
set age(value: number){
if(value < 0) return;
this._age = value;
}
// // 定义方法,用来获取name属性
// getName(){
// return this._name;
// }
// // 定义方法,用来设置name属性
// setName(value: string){
// this._name = value;
// }
// // 定义方法访问age属性
// getAge(){
// return this._age;
// }
// // 定义方法修改age;
// setAge(value: number){
// // 修改前就可以做判断,如果传入的值是负数,我们将不做任何修改
// if(value < 0) return;
// this._age = value
// }
}
// 实例化一个Person类
const per = new Person('孙悟空',18);
/**
* 一、现在属性是在对象中设置的,而且可以任意的被修改,
* 属性可以任意被修改将会导致对象中的数据变得非常不安全,所以我们要解决这个问题;
* 二、通过在class类内部设置访问和修改属性的方法,来间接安全的操作类中的属性,设置set和get方法;
*
*/
// 调用类中定义的方法,来访问或者修改name属性
// console.log(per.getName());
// per.setName('jack');
// console.log(per.getAge());
// per.setAge(-33) //传入的是负数,无法修改age值,达到我们需要的效果
// per._name = 'jack';
// per._age = -33; 属性“_age”为私有属性,只能在类“Person”中访问。
// 通过getter方法设置的方法,可以直接使用per.name,这句实际是在执行getter设置的方法,不是直接访问的属性
console.log(per.name);
per.name = 'jack';
console.log(per.age);
per.age = -33;
console.log('per:',per);
/* 三、protected 受保护的属性 */
class A{
protected num: number;
constructor(num: number){
this.num = num;
}
}
class B extends A{
test(){
console.log(this.num);
}
}
const b = new B(123);
// b.num = 33; //属性“num”受保护,只能在类“A”及其子类中访问。
/* 四、定义类中属性的简写方式 */
class C{
// 可以直接将属性定义在构造函数中
constructor(public name: string,public age: number){
}
}
/* 上述简写形式等价于下方代码 */
/* class C{
name: string;
age: number;
constructor(name: string,age: number){
this.name = name;
this.age = age;
}
} */
const c = new C('wangwu',12);
console.log('C',c);
})();
泛型
泛型的作用就是在我们对类型不明确的时候,给我们创造一个变量,用这个变量来表示变量的类型,来达到约束类型的效果;
一、在定义函数或是类时,如果遇到类型不明确时,就可以使用泛型
二、泛型可以同时指定多个
三、T extends Inter 表示泛型必须是Inter的实现类(子类)
(() => {
// TS中的泛型
// 作用:是在我们对类型不明确的时候,给我们创造一个变量,用这个变量来表示变量的类型,来达到约束类型的效果
/* function fn(a: any): any{ //不确定a和fn返回值的类型,使用any可以解决问题,但是我们前面说过指定any类型的话会让ts失去类型的判断,所以这样做是❌
return a;
} */
/**
* 一、在定义函数或是类时,如果遇到类型不明确时,就可以使用泛型
*/
function fn<T>(a: T): T{
return a;
}
// 可以直接调用具有泛型的函数
let result = fn(10); // 不指定泛型,TS可以自动对类型进行推断;但有时候逻辑复杂时,也需要我们去指定泛型
console.log(result); //let result: number
// 指定泛型
let result2 = fn<string>('hello,泛型');
console.log(result2);
/* 二、泛型可以同时指定多个 */
function fn2<T, K>(a: T,b: K):T{
console.log(b);
return a;
}
// 调用多个泛型的函数
fn2<number, string>(999,'www');
console.log(fn2<number, string>(999,'www'));
/* 三、T extends Inter 表示泛型必须是Inter的实现类(子类) */
interface Inter{
length: number;
}
function fn3<T extends Inter>(a: T): number{
return a.length;
}
// fn3([]) 此处传入的参数必须要有length属性才可以,也就是说必须是Inter的实现类
class MyClass<T>{
name: T;
constructor(name: T){
this.name = name;
}
}
const mc = new MyClass<string>('孙悟空');
console.log('mc:',mc);
})();
重绘以及回流
重绘:html元素因属性发生改变或者样式变动但是 在不影响布局的情况下(重点注意)会触发重绘。
有哪些属性会触发重绘呢,例如:
outline
visibility
color
background-color
等一切,比如修改样式,但是不会改变布局一般都会触发重绘,但是例如position、left等属性会影响元素的位置,那触发就不是重绘了而是回流
回流:布局或者属性发生改变的时候后,触发回流。
例如: js动态新增一个dom节点、设置宽高、设置位置等,一切会改变布局的行为都会触发回流
非常重要的知识点
回流一定会触发重绘,(布局都变了,你元素肯定要重新渲染),重绘不一定会触发回流
优化css,css提高性能的方法
内联首屏关键CSS、异步加载CSS、资源压缩、合理使用选择器、减少使用昂贵的属性、不要使用@import
Css盒模型
Content padding border margin
正常模型: box-size:content-box
怪异模型: box-sizing:border-box
正常盒子加边距像外扩,怪异模型像内扩
Css选择器
id选择器:
作用 : 选中对应id属性值的元素
例子 : <p id="A">段落1</p>
注意 : id的属性值只能给1个,可以重复利用,不能以数字开头
元素选择器:
作用 : 选中对应标签中的内容
例:p{} , div{} , span{} , ol{} , ul{}
类选择器:
作用 : 选中对应class属性值的元素
例子 : <p class="A">段落1</p>
注意:class里面的属性值不能以数字开头,如果以符号开头,只能是’_‘或者’-'这两个符号,其他的符号不可以,一个class里面可以有多个属性值
通配符选择器
作用 : 让页面中所有的标签执行该样式,通常用来清除间距
例子 : *{
margin: 0; //外间距
padding: 0; //内间距
}
群组选择器
作用 : 同时选中对应选择器的元素
div,p,h3,.li2{
font-size: 30px;
}
后代选择器
作用:后代选择器也叫包含选择器,祖先元素直接或间接的包含后代元素
/* 后代选择器(包含选择器),选择到的是box下面的所有后代p */
.box p{
background-color: yellow;
}
<div class="box">
<p>0000</p>
<div>
<p>11111</p>
<p>22222</p>
</div>
<p>444</p>
</div>
所有p标签变成黄色
子代选择器
作用:父元素直接包含子元素,子元素直接被父元素包含
<style>
/*子选择器选中的是.box下所有的儿子p
.box>p{
background-color: yellow;
}
</style>
<div class="box">
<p>0000</p>
<div>
<p>11111</p>
<p>22222</p>
</div>
<div class="box2">
<p>333</p>
</div>
<p>444</p>
</div>
0000和444变成黄色
相邻兄弟选择器
<style>
/* 相邻兄弟,会选择到box后面紧挨着的p,那么就是内容为111的p标签 */
.box p{
background-color: yellow;
}
</style>
<p>000</p>
<div class="box">盒子1</div>
<p>111</p>
111标签变黄
.通用兄弟选择器
<p>000</p>
<div class="box">盒子1</div>
<p>111</p>
<p>222</p>
<p>333</p>
<div>
<p>44444</p>
</div>
<p>5555</p>
<style>
/*通用兄弟选择器,会选择到.box后面所有的兄弟p,那么就是除了内容为'44444'以外的所有p*/
.box~p{
width: 200px;
height: 200px;
background-color: yellow;
}
</style>
行级元素:和其他的元素在一行上,高度行高以及外边距和内边距都不可改变,文字图片的宽度不可改变,只能容纳文本或者其他行内元素;其中img是行内元素
块级元素: 总是在新行上开始,高度,行高以及外边距内边距都可以控制,可以容纳内敛元素和其他元素:
行级元素转换为块级元素的方法:display:block;
flex:
将块级元素设为flex:.box{display:flex;}
将行级元素设为flex:.box{display:inline-flex;}
媒体查询
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<div id="div0">
</div>
</body>
<style>
#div0{
width: 100px;
height: 200px;
}
@media screen and (min-device-width:200px) and (max-device-width:300px){
#div0{
background-color: red;
}
}
@media screen and (min-device-width:301px) and (max-device-width:500px){
#div0{
background-color: blue;
}
}
</style>
</html>
Flex属性:
row:默认值,表示flex子项水平方向从左到又进行排序,此时水平方向上轴线为主轴方向,
Rwo-reverse: 与row相反,水平方向轴线为主轴方向,fkex子项排列从有向左进行排序
Column:表示flex子项垂直方向上从上到下进行排列,此时垂直方向轴线为主轴方向
column-reverse: 与column相反,垂直向轴线为主轴方向,elex子项排列,为从下到上
flex-start:默认值,表示Flex子项与行的起始位置对齐
flex-end :表示flex子项与行的结束位置对齐
Center:表示flex子项与行中间对齐
space-between:表示两端对齐,中间间距相等
space-around:表示间距相等,中间间距是两端间距的二倍
background-attachment 将背景附着到页面不会随着页面滚动而滚动
更多flex详情
ES6
var:在ES5中,顶层对象的属性和全局变量是等价的,用var声明的变量既是全局变量,也是顶层变量:
顶层对象,在浏览器环境指的是window对象,在 Node 指的是global对象
使用var声明的变量存在变量提升的情况
使用var,我们能够对一个变量进行多次声明,后面声明的变量会覆盖前面的变量声明:
在函数中使用使用var声明变量时候,该变量是局部的
而如果在函数内不使用var,该变量是全局的
————————————————
Let : 不允许重复声明,块级作用域,不存在变量提升
let是ES6新增的命令,用来声明变量
用法类似于var,但是所声明的变量,只在let命令所在的代码块内有效,不存在变量提:
只要块级作用域内存在let命令,这个区域就不再受外部影响
使用let声明变量前,该变量都不可用,也就是大家常说的暂时性死区:
let不允许在相同作用域中重复声明
注意的是相同作用域,下面这种情况是不会报错的,因此,我们不能在函数内部重新声明参数
————————————————
Const: 只读变量,不能被改变,必须赋值
声明一个只读的常量,一旦声明,常量的值就不能改变:
一旦声明变量,就必须立即初始化,不能留到以后赋值
如果之前用var或let声明过变量,再用const声明同样会报错
const实际上保证的并不是变量的值不得改动,而是变量指向的那个内存地址所保存的数据不得改动:
对于简单类型的数据,值就保存在变量指向的那个内存地址,因此等同于常量
对于复杂类型的数据,变量指向的内存地址,保存的只是一个指向实际数据的指针,const只能保证这个指针是固定的,并不能确保改变量的结构不变
————————————————
symbol
Symbol是ES6中引入的一种新的基本数据类型,用于表示一个独一无二的值,不能与其他数据类型进行运算。它是JavaScript中的第七种数据类型,与undefined、null、Number(数值)、String(字符串)、Boolean(布尔值)、Object(对象)并列。
————————————————
变量提升
console.log(abc) //声明变量明明在输出之后,可是他却找了abc,有些场景下会出现问题
var abc = ’123‘;
var声明的变量存在变量提升,即变量可以在声明之前调用,值为undefined
let和const不存在变量提升,即它们所声明的变量一定要在声明后使用,否则报错
————————————————
暂时性死区:
var不存在暂时性死区
let和const存在暂时性死区,只有等到声明变量的那一行代码出现,才可以获取和使用该变量
————————————————
块级作用域:
var不存在块级作用域
let和const存在块级作用域
————————————————
重复声明:
var允许重复声明变量
let和const在同一作用域不允许重复声明变量
————————————————
修改声明的变量:
var和let可以
const声明一个只读的常量。一旦声明,常量的值就不能改变
————————————————
模板字符串:
是增强版的字符串,用反引号(`)标识,可以当作普通字符串使用,也可以用来定义多行字符串
let firstName = "Bill";
let lastName = "Gates";
let text = `Welcome ${firstName}, ${lastName}!`;
//结果为 : Welcome Bill, Gates!
//也可以进行一些数字运算
let price = 10;
let VAT = 0.10;
let total = `Total: ${(price * (2 VAT))}`;
//结果为 : Total: 21
//也可以插入html模板
let header = "Templates Literals";
let tags = ["template literals", "javascript", "es6"];
let html = `<h2>${header}</h2><ul>`;
for (const x of tags) {
html = `<li>${x}</li>`;
}
————————————————
解构赋值ES6 允许按照一定模式,从数组和对象中提取值,对变量进行赋值
const arr = ['foo','bar','styring']
console.log(...arr) //结果:foo bar styring
es6新增方法
//构造函数新增的方法
Array.from():将两类对象转为真正的数组:类似数组的对象和可遍历(iterable)的对象(包括 ES6 新增的数据结构 Set 和 Map)
可以接受第二个参数,用来对每个元素进行处理,将处理后的值放入返回的数组.
Array.of():用于将一组值,转换为数组
没有参数的时候,返回一个空数组
当参数只有一个的时候,实际上是指定数组的长度
参数个数不少于 2 个时,Array()才会返回由参数组成的新数组
//实例对象新增的方法
copyWithin():将指定位置的成员复制到其他位置(会覆盖原有成员),然后返回当前数组
find()、findIndex():find()用于找出第一个符合条件的数组成员
fill():使用给定值,填充一个数组
entries(),keys(),values():
keys()是对键名的遍历
values()是对键值的遍历
entries()是对键值对的遍历
includes():用于判断数组是否包含给定的值
flat(),flatMap():将数组扁平化处理,返回一个新数组,对原数据没有影响
//对象的遍历属性:
for...in:循环遍历对象自身的和继承的可枚举属性(不含 Symbol 属性)
Object.keys(obj):返回一个数组,包括对象自身的(不含继承的)所有可枚举属性(不含 Symbol 属性)的键名
Object.getOwnPropertyNames(obj):回一个数组,包含对象自身的所有属性(不含 Symbol 属性,但是包括不可枚举属性)的键名
Object.getOwnPropertySymbols(obj):返回一个数组,包含对象自身的所有 Symbol 属性的键名
Reflect.ownKeys(obj):返回一个数组,包含对象自身的(不含继承的)所有键名,不管键名是 Symbol 或字符串,也不管是否可枚举
//对象新增的方法
Object.is():严格判断两个值是否相等,与严格比较运算符(===)的行为基本一致,不同之处只有两个:一是 0不等于-0,二是NaN等于自身
Object.assign():
Object.assign()方法用于对象的合并,将源对象source的所有可枚举属性,复制到目标对象target
Object.assign()方法的第一个参数是目标对象,后面的参数都是源对象
注意:Object.assign()方法是浅拷贝,遇到同名属性会进行替换
Object.getOwnPropertyDescriptors():返回指定对象所有自身属性(非继承属性)的描述对象
Object.setPrototypeOf():用来设置一个对象的原型对象
Object.getPrototypeOf():用于读取一个对象的原型对象
Object.keys():返回自身的(不含继承的)所有可遍历(enumerable)属性的键名的数组
Object.values():返回自身的(不含继承的)所有可遍历(enumerable)属性的键对应值的数组
Object.entries():返回一个对象自身的(不含继承的)所有可遍历(enumerable)属性的键值对的数组
Object.fromEntries():用于将一个键值对数组转为对象
super关键字
this关键字总是指向函数所在的当前对象,ES6 又新增了另一个类似的关键字super,指向当前对象的原型对象
————————————————
箭头函数
1、如果箭头函数不需要参数或需要多个参数,就使用一个圆括号代表参数部分
2、如果箭头函数的代码块部分多于一条语句,就要使用大括号将它们括起来,并且使用return语句返回
3、如果返回对象,需要加括号将对象包裹
4、注意点:
函数体内的this对象,就是定义时所在的对象,而不是使用时所在的对象
不可以当作构造函数,也就是说,不可以使用new命令,否则会抛出一个错误
不可以使用arguments对象,该对象在函数体内不存在。如果要用,可以用 rest 参数代替
不可以使用yield命令,因此箭头函数不能用作 Generator 函数
————————————————
export和export default
是用来导出常量、函数、文件、模块的。是ES6语言。
暴露数据 语法:
分别暴露 -----------------------------------
在要暴露的数据前面加上 export
export let schoe = '我是笨蛋’
export function WSBD(){
log(‘我是一个不努力,又没天赋的笨蛋’)
}
-----------------------------------
统一暴露 -----------------------------------
let schoe = '我是笨蛋’
function WSBD(){
log(‘我是一个不努力,又没天赋的笨蛋’)
}
export {schoe ,WSBD}
-----------------------------------
默认暴露 -----------------------------------
export default {
SCHOL:‘ATSB’,
chnge:function(){
log(‘我是就是啥也不会还很狂的人’)
}
}
-----------------------------------
引用语法
1.通用的导入方法
import * as from ‘文件地址 如 ./src/js/m1.js’
2. 结构赋值形式引用
import {schoe ,WSBD} from “文件地址” //应对分别暴露
如果需要引入两个并且名字重复,直接引用会报错 可以使用别名 语法如下:
import {schoe as bieming} from “文件地址”
使用时直接用 别名 bieming即
import {default as m3} from “文件地址” //应对默认暴露
但是不能直接引用 default 必须取别名
3.简便形式 只能针对默认暴露
import m3 from “./src/js/m3.js”
//--------------第一种方式:定义变量与导出分开-----------------------------
var one = "export导出"
var two=["AAA","BBB","CCC"]
export { one, two }
//--------------导出与定义变量直接一起写--------------------------------
export var three="直接导出"
在使用该变量的地方引入
import {one,two,three} from "../js/test.js"
//打印
console.log(one "," two "," three);
输出结果为:
详情
————————————————
Proxy 与 Reflect
是 ES6 为了操作对象引入的 API 。
Proxy 可以对目标对象的读取、函数调用等操作进行拦截,然后进行操作处理。它不直接操作对象,而是像代理模式,通过对象的代理对象进行操作,在进行这些操作时,可以添加一些需要的额外操作。
Reflect 可以用于获取目标对象的行为,它与 Object 类似,但是更易读,为操作对象提供了一种更优雅的方式。它的方法与 Proxy 是对应的。
*** includes***
判断数组中是否含有指定元素,有的话返回true
如: console.log(shuzu.includes(‘西游记’))
*** 幂运算 ***
console.log(2 ** 10)
console.log(Math.pow(2,10))
这个两个东西是一样的 输出结果为(1024)
————————————————
VUE
生命周期
开始创建->初始化数据->编译模板->挂载dom->数据更新重新渲染虚拟 dom->最后销毁。这一系列的过程就是vue的生命周期。所以在mounted阶段真实的DOM就已经存在了。
创建前:beforecreate
JS方法还未获取到
创建后: created
已经获取到JS但是没有页面dom可以请求数据可以修改数据
挂载前:beforemounted
已经有页面有数据但是没有dom,获取不到标签
挂载后:mouted
有数据有dom
更新前:beforeupdate
执行这个函数是页面的数据是旧的但是data中的数据是最新的
更新后:updata
页面和数据已经更新都是最新的
销毁前: beforeDestory
进入销毁阶段,这个时候data和methods都是可用状态
销毁后:destroyed
销毁成功
------------------------生命周期结束--------------------------------------
基础概念(个人理解)
1.想让Vue工作,就必须创建Vue实例且要传入一个配置对象:
2.真实开发中只有一个vue实例,并且会配合组件一起使用
3.vue实例和容器是11对应的
{{XXX}}中的xxx要写表达式,且xxx可以自动读取到data中所有属性:
注意区分:
JS表达式 和js代码(语句)
1.表达式:一个表达式会产生一个值 ,可以在任意一个需要值得地方:
(1) a
(2) a b
(3) x === y ? ‘a’ : ‘b’
js代码(语句)
1. if(){}
2. for(){}
Vue模板语法2大类
1.插值语法:
功能:用于解析标签体内容
用法: {{xxx}} xxx是js表达式 且可以读取到data中的所有属性
2.指令语法:
功能 :用于解析标签(包括:标签属性 标签体内容/内容事件)
举例: v-bind:href="/link/to?link=https://blog.csdn.net/tutodelinglimgho/article/details/xxx" 或 简写为 :href=“xxx” ,xxx同样要写js表达式
且可以读到data中的所有属性
v-bind 绑定数据 一般用于页面
v-model 绑定数据一般用于表单与用户交互
el有两种写法
(1)new Vue时候配置el属性
(2)先创建Vue实例,随后再通过vm。¥mount(‘#root’)指定el的值
data有两种写法
(1)对象试
(2)函数式
如何选择:实际开发中必须使用data函数式
一个重要的原则: vue管理的函数,不要写箭头函数,一旦写了箭头函数,this就再也不是vue实例了
object.defineProperty
给对象添加属性 需要传三个属性
let number = 10;
Object.definePropert(person,‘age’,{value:18} // 添加的位置名字(person),属性名(age),属性值(18)
enumerable:true, //enumerable控制属性是否可以枚举默认为false
writable:true //控制属性是否可以被修改 默认为false
configurable:true //控制属性是否可以被删除
get(){
return number
//当有人读取person的age属性时,get函数(getter)就会被调用,并且返回值
}
set(value){
number = value
//当有人修改person的age属性时 ,set函数就会调用 并返回新值
}
)
object.defineProperty 默认是无法进行枚举的 //枚举:就是无法进行遍历
vue修饰符
v-on 或 @cxxx 绑定事件 xxx是事件名
123
Vue事件修饰符;
<button @click.???>
1. prevent: 阻止默认事件
2. stop 阻止事件冒泡
3. once 事件只触发一次
4. capture 使用事件的捕获模式
5. self 只有event。target是当前操作的元素时才会触发事件:
6. passive 事件的默认行为立即执行,无需等待事件回调执行完毕
vue中的按键别名:
回车 => enter
删除 => delete(捕获删除和 退格)
退出 = > ESC
空格 => space
换行 => tab (特殊,必须配合keydown去使用)
系统修饰键: ctrl 、 alt 、 shift 、 meta
配合keyup使用:按下修饰键的同时,再按下其他键才回触发
配合keydown使用 正常触发事件
使用场景如在一个输入框内检测用户输入什么按键之前返回指定的值
使用方法: <input type="text" placeholder="按下回车提示输入" @keyup.ctrl.y="AAA"> //只有用户使用ctrl Y时 才回触发
计算属性computed与watch
定义:要用的属性不存在,要通过已有的属性计算得来
原理;底层借助了objecet.definerproperty方法提供的getter和setter
get函数在初次读取数据时调用,在当依赖数据发生变化时调用,
优势:与methods实现相比,内部有缓存机制,效率更高
监视属性watch:
1.当被监视的属性变化时,回调函数自动调用,进行相关操作
2.监视的属性必须存在,才能进行监视!!
3.监视的两种写法l
vew Vue 时使用watch配置
通过vm,¥warch监视
深度检测:
(1).vue中的watch默认不监测对象内容值得改变
配置deep:true 可以检测对象内部改变(多层)
备注:
Vue自身可以检测对象内部值得改变,但是warch默认不可以
使用warch时根据数据的具体结构,决定是否采用深度检测
watch:
1.是观察的动作,
2.应用:监听props,$emit或本组件的值执行异步操作
3.无缓存性,页面重新渲染时值不变化也会执行
watch是一个观察的动作当一条数据影响多条数据的时候就需要用watch
computed实现:
computed特点:
不支持缓存,数据变,直接会触发相应的操作
监听的函数接收两个参数,第一个参数是最新的值;第二个参数是输入之前的值;
当一个属性发生变化时,需要执行对应的操作;一对多;
监听的是这个属性自身的变化,且不会操作缓存
监听数据必须是data中声明过或者父组件传递过来的props中的数据,当数据变化时,触发其他操作,函数有两个参数,是一个计算属性,类似于过滤器,对绑定到view的数据进行处理,当一个属性受多个属性影响的时候就需要用到computed
深度监测
深度监测:VUE中watch默认是不检测对象内部的改变(1层),配置deep:true可开启监测对象内部的值改变(多层)
备注: vue自身可以检测对象内部值得改变,但是vue提供watch默认不可以
Computed与watch
Computed是计算属性watch是监听一个值得变化然后进行回调,使用场景computed当一个属性受到多个属性影响时使用computed比如购物车,watch 当条数据影响多条数据的时候使用watch比如搜索框
样式绑定V-bind
v-if条件判断
template
template 搭配v-if进行条件判断代替div,但不能使用v-show
vue自定义指令
ref属性:
被用来给元素或子组件注册引用信息(id的替代者),应用在html标签上获取的是真实DOM元素,应用在组件标签上获取的是组件实例对象(vc)拿到
使用方式:
打标识:</h1 ref="xxx"></H1/> 或 <School ref="xxx"></School>
获取:this.$refs.xxx
props配置项:
功能:让组件接收外部传过来的数据
传递数据:<Demo name="xxx"/>
接收数据:第一种方式(只接收):props:[‘name’]
第二种方式(限制数据类型):props:{name:String}
第三种方式(限制类型、限制必要性、指定默认值):
props:{
name:{
type:String, 类型
required:true, 必要性
default:‘老王’ 默认值
}
}
props是只读的,Vue底层会监测你对props的修改,如果进行了修改,就会发出警告,若业务需求确实需要修改,那么请复制props的内容到data中一份,然后去修改data中的数据
mixin混入
功能:可以把多个组件公用的配置提取成一个对象
使用方式:
第一步:定义混合
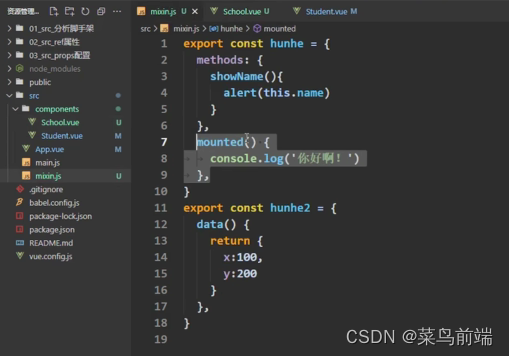
局部混入mxins:{xxx}
全局混入(在main.js中引入).Vue.mixin(xxx)
可以理解成多个组件使用一段js
如果混入中定义的数据,页面中也有那么已页面的值为主,如果混入中定义的生命周期钩子与混入中相同则两个一起执行(混入钩子优先执行)
插件
功能:用于增强Vue
本质:包含install方法的一个对象,install的第一个参数是Vue,第二个以后的参数是插件使用传递的数据
定义插件:
对象install = function(Vue,options){
功能1如:
Vue.filter()
功能2如:
Vue.directive()
}
在main.js中使用插件 用法 Vue.use(引用)
回话存贮sessionStorage 与本地存贮localStorage
浏览器本地存储数据:localStorage.setItem
localStorage浏览器关闭数据不会消失
sessionStorage API与localStorage一样 但关闭浏览器会消失数据
全局事件总线 创建$bus
消息订阅与发布
插槽
Vuex
vuex是一个专门为vue.js开发的状态管理模式,每一个vuex应用核心就是store(仓库)。store基本上就是一个容器,它包含着你的应用中大部分的state(状态)
vuex的状态存储是响应式的,当 vue组件中store中读取状态时候,若store中的状态发生变化,那么相应的组件也会相应地得到高效更新
State: 存储数据的地方,定义了应用状态的数据结构,可以在这里设置默认的初始状态
Mutations: 唯一可以修改state的地方,且必须是同步函数。
Actions: 可以编辑逻辑,用于提交muatation, 而不是直接变更状态,可以包含任意异步操作。
Getters: 简化数据的地方,允许组件从Stroe中获取数据, mapGetters辅助函数仅仅是将store中的getter映射到计算属性。
Module: modules,可以让每一个模块拥有自己的state、mutation、action、getters,使得结构非常清晰,方便管理;如果所有的状态或者方法都写在一个store里面,将会变得非常臃肿,难以维护。
vuex辅助函数
mapState — mapGetters --mapAction – mapMutations –
防止VUEX数据刷新丢失 可以在大仓库中引入
import createPersistedState from ‘vuex-persistedstate’
并引入
-----------------------------------VUEX结束----------------------------------------
keep-alive
是一个自带的组件,主要保留组件状态和避免重新渲染
router路由以及路由传参
路由守卫
vue基础与问题
条件渲染指令 v-if
列表渲染指令 v-for
属性绑定指令 v-on
双向绑定指令 v-model
v-model深入
可以使用.native可以把当前事情变为dom事件,给组件根标签集体加上事件
v-cloak指令
本质是一个特殊属性,vue实例创建完毕并接管容器后,会删掉v-cloak属性,使用css配合v=clock可以解决网速慢时展示出{{xxx}}属性
v-once指令:
v-onve所有在节点初次动态渲染后,就视为静态内容了。
以后数据的改变不会引起v-once所在结构的更新,可以用于优化性能。
v-pre:
v-once所在节点在初次动态渲染后,就视为静态内容
以后数据的改变不会引起v-onve所在结构的更新,可以用于优化性能
vue中的key有什么作用?(key的内部原理)
虚拟DOM中key的作用:key是虚拟DOM中对象的标识,当数据发生变化时,Vue会根据【新数据】生成【新的虚拟DOM】,随后Vue进行【新虚拟DOM】与【旧虚拟DOM】的差异比较,比较规则如下:
对比规则:
旧虚拟DOM中找到了与新虚拟DOM相同的key:
若虚拟DOM中内容没变, 直接使用之前的真实DOM
若虚拟DOM中内容变了, 则生成新的真实DOM,随后替换掉页面中之前的真实DOM
旧虚拟DOM中未找到与新虚拟DOM相同的key:创建新的真实DOM,随后渲染到到页面
用index作为key可能会引发的问题:
若对数据进行逆序添加、逆序删除等破坏顺序操作:会产生没有必要的真实DOM更新 ==> 界面效果没问题, 但效率低
若结构中还包含输入类的DOM:会产生错误DOM更新 ==> 界面有问题
开发中如何选择key?
最好使用每条数据的唯一标识作为key,比如id、手机号、身份证号、学号等唯一值
如果不存在对数据的逆序添加、逆序删除等破坏顺序的操作,仅用于渲染列表,使用index作为key是没有问题的
v-show 和 v-if指令的共同点和不同点?
v-show是css切换,v-if是完整的销毁和重新创建,如果频繁切换时用v-show,运行时较少改变用v-if
Mvvm:
Model: 模型层负责处理页面逻辑
View: 负责数据模型将页面展示出来,简单来说就是html
Viewmodel : 负责将model和view进行连接
VUE2与vue3的区别:
双向数据绑定原理发生发生改变 vue2是通过es6的api objectdfinepropert对数据进行劫持结合发布订阅vue3是通过es6的proxy对数据代理并且加入typescript,vue3可以拥有多个跟节点
路由跳转
声明式:(标签跳转)<router-link :to“地址”>
编程式: (JS跳转) router.push(地址)
路由传参
通过This.$router.params.id接收
路由name匹配,通过params参数
通过this. $route。queryid 接收参数
params和query的区别(怎么定义 vue-router 的动态路由? 怎么获取传过来的值?)
query语法:this.$ router.push({path:“地址”,query:{id:“123”}});这是传递参数
this.$route.query.id;这是接收参数
params语法: this. $router.push({name:“地址”,params:{id:“123”}});这是传递参数
this. $route.params.id; 这是接收参数
$router 和 $route 的区别
$ router是用来操作路由的 $ route是用来获取路由信息的。
- $ router是VueRouter的一个实例
他包含了所有的路由,包括路由的跳转方法,钩子函数等,也包含一些子对象(例如history)
当导航到不同url,可以使用this. r o u t e r . p u s h 方法,这个方法则会向 h i s t o r y 里面添加一条记录,当点击浏览器回退按钮或者 t h i s . router.push方法,这个方法则会向history里面添加一条记录,当点击浏览器回退按钮或者this. router.push方法,这个方法则会向history里面添加一条记录,当点击浏览器回退按钮或者this.router.back()就会回退之前的url。
this.$route
相当于当前激活的路由对象,包含当前url解析得到的数据,可以从对象里获取一些数据,如name,path等。
keep-alive
keep-alive 是 vue 中的内置组件,能够在组件切换过程中将状态保留在内存中,防止重复的渲染 DOM;
keep-alive 包裹动态组件时,会缓存不活动的组件实例,而不是销毁它们;
设置了 keep-alive 缓存的组件,会多出两个生命周期钩子(activated 和 deactivated )
vue.nextTick() 方法
在下次 DOM 更新循环结束之后执行延迟回调。在修改数据之后立即使用这个方法,获取更新后的 DOM。
使用:
this.$nextTick(function(){
console.log(that.$refs.aa.innerText); //输出:修改后的值
})
vue-router 有哪几种导航钩子?
1.全局导航钩子:router.beforeEach(to,from,next)作用:跳转前进行判断拦截、组件内的钩子、单独路由独享组件
2、路由独享钩子可以在路由配置上直接定义 beforeEnter
3、组件内的导航钩子有三种:
beforeRouteEnter 在进入当前组件对应的路由前调用
beforeRouteUpdate 在当前路由改变,但是该组件被复用时调用
beforeRouteLeave 在离开当前组件对应的路由前调用=
请求拦截器:
可以在请求发出去之前做一些事情,可以在config中配置对象,headers请求头
响应拦截器:
请求成功或失败做一些事情
让css只在当前页面生效:
在style 中加入scoped
为什么使用key?
做一个唯一标识, Diff 算法就可以正确的识别此节点。作用主要是为了高效的更新虚拟 DOM。
什么防抖与节流?
防抖和节流都是防止某一时间频繁触发,但是原理却不一样。
防抖:Debounce将前面所有触发取消,最后一次执行规定时间内才能触发,也就是说如果连续触发只能执行一次,(大部分应用场景搜索框等)
<template>
<div>
<el-input v-model="inputVal" placeholder="请输入内容" @input="inputChange"></el-input>
</div>
</template>
<script>
//引入lodash
import lodash from "lodash";
export default {
name: "HelloWorld",
data() {
return {
inputVal: "",
};
},
methods: {
inputChange: lodash.debounce(function (val) {
console.log("---输入框内容(lodash)---", val); //业务逻辑
console.log("---发送请求---"); //业务逻辑
}, 1000),
},
};
</script>
节流:throttle将在规定的间隔时间范围内不会重复触发回调,只有大于这个时间间隔才会触发回调,把频繁触发变为少量触发(列如查询五秒内只能使用一次)
<template>
<div class="main">
<el-button type="plain" @click="search">搜索</el-button>
</div>
</template>
<script>
import lodash from "lodash";
export default {
name: "HelloWorld",
methods: {
search: lodash.throttle(
function () {
console.log("---发送请求---"); //业务逻辑
},
3000,
{ trailing: false } //一定要传入这个参数否则的话在3秒内多次点击会调用2次
),
},
};
</script>
vue.cli 中使用自定义组件
第一步:在components目录新建组件文件(indexPage.vue),script一定要export default {}。
第二步:在需要用的页面(组件)中导入:import indexPage from ‘@/components/indexPage.vue’
第三步:注入到vue子组件的components属性上面,components:{indexPage}
第四步:在template视图view中使用,例如有indexPage命名,使用的时候则index-page
为什么避免 v-if 和 v-for 一起用?
当 Vue 处理指令时,v-for 比 v-if 具有更高的优先级,通过v-if 移动到容器元素,不会再重复遍历列表中的每个值。取而代之的是,只检查它一次,且不会在 v-if 为否的时候运算 v-for
路由守卫 / 导航守卫
既然是守卫,首先是对咱们后台页面访问的一层保护,如果我没有进行登陆过,后台的操作页面是不允许用户访问的
我们是用到vue路由中的一个钩子函数beforeEach,那么这个函数中有三个参数,分别是to from next
to是去哪里 from是从哪里来 next下一步说通俗点就是放行
VUE3
vue3中组件中模板可以没有根标签
vite
setup
ref函数
recative函数
vue中的响应式
监视属性
watch
watchEffect函数
Vue3生命周期
组合式API在可以在setup中使用,并且要改名在前面加on,也可以像VUE2中在外部正常书写(不用改名,如果一起用setup中的钩子优先级会更高)
hook
shallowReactive 和 shallowRef
readonly与shallowReadonly
toRaw 和 markRaw
自定义ref
provide与iinject
响应数据的判断
Composition API的优势
Fragment
嵌套多级组件时可用Teleport将部分结构传送到总的html结构中
Suspense异步组件
vue3的改变
data应该被声明为一个函数
uniapp
uniapp里没有div,都是用view标签代替。
使用图片需要通过import引入,并在data()里返回,最后才能绑定到标签上去。(图片标签)
onLoad()为加载函数,用的多一点,其他生命周期函数的可以去官网看
接口请求(使用原生的即可)
uni.navigateTo(OBJECT):常用,保留当前页面,跳转到应用内的某个页面。
uni.redirectTo(OBJECT):不保留当前页面,跳转到应用内的某个页面。(与上面的区别一样,场景不同的)
window.location.href:跳转站外,还得原生JS
应用生命周期仅可在App.vue中监听
onLaunch :当uni-app 初始化完成时触发(全局只触发一次)
App.vue里的onLaunch中option作用:获取用户进入小程序或退出小程序的场景
onShow :当 uni-app 启动,或从后台进入前台显示 //监听用户进入小程序
onHide :当 uni-app 从前台进入后台 //监听用户离开小程序
onError :当 uni-app 报错时触发
onUniNViewMessage :对 nvue 页面发送的数据进行监听
页面生命周期(在页面中添加)
(1)onLoad (监听页面加载)
(2)onShow (监听页面显示)
(3)onReady (监听页面初次渲染完成)
(4)onHide (监听页面隐藏)
Echarts的使用
- 步骤1:引入 echarts.js 文件
echarts是一个 js 的库,当然得先引入这个库文件
<script src="https://blog.csdn.net/tutodelinglimgho/article/details/js/echarts.min.js"></script>
- 步骤2:准备一个呈现图表的盒子
这个盒子通常来说就是我们熟悉的 div ,这个 div 决定了图表显示在哪里
<div id="main" style="width: 600px;height:400px;"></div>
- 步骤3:初始化 echarts 实例对象
在这个步骤中, 需要指明图表最终显示在哪里的DOM元素
var myChart = echarts.init(document.getElementById('main'))
- 步骤4:准备配置项
这步很关键,我们最终的效果,到底是显示饼图还是折线图,基本上都是由配置项决定的
var option = {
xAxis: {
type: 'category',
data: ['小明', '小红', '小王']
}, //直角坐标系 中的 x 轴, 如果 type 属性的值为 category ,那么需要配置 data 数据, 代表在 x 轴的呈现
yAxis: {
type: 'value'
}, //直角坐标系 中的 y 轴, 如果 type 属性配置为 value , 那么无需配置 data , 此时 y 轴会自动去series 下找数据进行图表的绘制
series: [
{
name: '语文', //分数的名字
type: 'bar', //表格的类型
data: [70, 92, 87], //分数
}
]
}
- 步骤5:将配置项设置给 echarts 实例对象
myChart.setOption(option)
注意: 坐标轴 xAxis 或者 yAxis 中的配置, type 的值主要有两种: category 和 value , 如果 type
属性的值为 category ,那么需要配置 data 数据, 代表在 x 轴的呈现. 如果 type 属性配置为 value ,
那么无需配置 data , 此时 y 轴会自动去 series 下找数据进行图表的绘制
axios与ajax
ajax
本身是针对MVC的编程,不符合现在前端MVVM的浪潮,基于原生的XHR开发,XHR本身的架构不清晰,已经有了fetch的替代方案,JQuery整个项目太大,单纯使用ajax却要引入整个JQuery非常的不合理。
优点:
1、无刷新更新数据
2、异步与服务器通信
3、前端和后端负载平衡
4、基于标准被广泛支持
5、界面与应用分离
缺点:
1、ajax不能使用Back和history功能,即对浏览器机制的破坏
2、安全问题 ajax暴露了与服务器交互的细节
3、对搜索引擎的支持比较弱
4、破坏程序的异常处理机制
5、违背URL和资源定位的初衷
6、ajax不能很好的支持移动设备
7、太多客户端代码造成开发上的成本
Ajax适用场景:
1、表单驱动的交互
2、深层次的树的导航
3、快速的用户与用户间的交流响应
4、类似投票、yes/no等无关痛痒的场景
5、对数据进行过滤和操纵相关数据的场景
6、普通的文本输入提示和自动完成的场景
Ajax不适用场景:
1、部分简单的表单
2、搜索
3、基本的导航
4、替换大量的文本
5、对呈现的操纵
//代码
$.ajax({
type: 'POST',
url: url,
data: data,
dataType: dataType,
success: function () {},
error: function () {}
});
ajax请求的五个步骤
创建XMLHttpRequest异步对象
设置回调函数
使用open方法与服务器建立连接
向服务器发送数据
在回调函数中针对不同的响应状态进行处理
————————————————
axios:
Axios 是一个基于 Promise 的 HTTP 库,可以用在浏览器和 node.js 中;是请求资源的模块;通过promise对ajax的封装。
简单理解为:封装好的、基于promise的发送请求的方法,因此不用设置回调函数,直接去调用then方法。
属性:url、method、data、responseType、.then、.catch…
从 node.js 创建 http 请求
支持 Promise API
客户端支持防止CSRF
提供了一些并发请求的接口(重要,方便了很多的操作)
axios有那些特性?
1、 在浏览器中创建 XMLHttpRequests
2、在node.js则创建http请求
3、支持Promise API
4、支持拦截请求和响应
5、转换请求和响应数据
6、取消请求
7、自动转换成JSON数据格式
8、客户端支持防御XSRF
9、提供了一些并发请求的接口(重要)
//get请求
// 第一种方式 将参数直接写在url中
axios.get('/getMainInfo?id=123')
.then((res) => {
console.log(res)
})
.catch((err) => {
console.log(err)
})
// 第二种方式 将参数直接写在params中
axios.get('/getMainInfo', {
params: {
id: 123
}
})
.then((res) => {
console.log(res)
})
.catch((err) => {
console.log(err)
})
POST
axios.post('/getMainInfo', {
id: 123
})
.then((res) => {
console.log(res)
})
.catch((err) => {
console.log(err)
})
ajax 可以直接使用同步方法,ajax可以直接实现跨域请求,而这两个很重要的功能axios都不可以,同步必须添加async和await 才可以,跨域只能通过代理来实现
原文地址
网络请求
使用ajax获取数据的时候,如果当前界面的地址和所需要的服务器地址,协议,域名,端口有一个不一样时就需要跨域
常用的请求方式
get:特点 参数大小有限制 请求可以缓存,请求是http应用层,数据传输的话,使用tcp传输只能发一次,只能用于查询,不会修改、增加。
Post:特点 参数在请求中参数没有大小限制
Delete:就是删除
浏览器与web页面安全
1.存储内容大小一般支持5MB左右(不同浏览器不一样)
2.浏览器通过window.sesslonStorage和window.localStoage属性实现本地存贮机制
3.相关api
xxxxStorage.setItem(‘key’,‘value’);
改方法接受键和值作为参数,会把键值对添加到存储中,如果键名存在,则更新其对应的值
xxxxStorage.getItem(‘person’);
改方法接受一个键名作为参数.返回键名对应的值
XXXStore.removeItem(‘key’);
该方法接受一个键名作为参数,并把该键名从存储中删除
xxxxStorage.clear()
该方法会清空存储的所有数据
4.备注
1.sesslonStorage存储的内容会随着浏览器窗机关闭而消失
2.LocalStorage存储的内容,需要手动清除才会消失
1.1Web页面安全
1.什么是同源、什么是同源策略、同源策略的表现是什么?
2.浏览器出让了同源策略的哪些安全性?
3.跨域解决方案有哪些?
4.JSONP如何实现?
5.CORS你了解哪些?
6.针对Web页面安全有哪些常见的攻击手段(XSS、CSRF)?
1.2 浏览器网络安全
1.什么是请求报文?
2.什么是响应报文?
3.HTTP缺点
4.HTTPS基础知识点
5.HTTPS流程
什么是同源?
跨域本质就是指两个地址不同原,不同源反面就是就是同源,而同源就是指URL的协议,域名和端口号都相同,则就是两个就是同源的URL,实例如下
// 非同源:协议不同
http://www.百度.com
https://www.百度.com
// 同源:协议、域名、端口号都相同
http://www.百度.com
http://www.百度.com?query=1
同源策略
同源策略是一个重要的安全策略,他用于限制一个origin的文档或者他们加载的加载的脚本如何与另一个原进行交互,其主要目的是为了保护用户信息的安全,防止恶意的网站窃取数据,是浏览器在Web页面层面做的保护。
同源策略的表现
既然同源是浏览器在web页面做的保护,主要有三个层面:DOM层,数据层,网络层
1.DOM层
同源策略限制了来自不同源的JavaScript脚本对当前DOM对象读写的操作
2.数据层
同源策略限制了不同源的站点读取当前站点的Cookie,lndexedDB,localstorage等数据
3.网络层
同源策略限制了通过XMHttpRequest等方式将站点的数据发送给不同原的站点
跨域分类
同源策略虽然保证了浏览器的安全,但是如果将这三个层面限制的过于严格,则会对后期的开发工作带来巨大的困难,所以浏览器需要在最严格的同源策略下做一下让步,这些让步是为了安全性与便捷性的权衡,跨域的方式就是浏览器让出了一些安全性和遵守同源策略下中取出的手段。
DOM层和数据层分类
根据同源策略,如果两个页面,无法相互操作DOM,访问数据,但是两个不同源之间进行通信比较常见的情形,典型的例子就是iframe窗口与父窗口之间的通信,实现dom层通信的方式有很多种。
2.2网络层面
根据同源策略,浏览器默认不允许XMLHttpRequest对象访问非同一站点的资源的,这会限制生产力,所以我们破解这种限制,实现跨域访问资源,目前广泛采用的主要有三种方式:
1.通过代理实现
同源策略是浏览器为了安全制定的策略,所以服务器端不会存在限制,这样我们就可以将请求打到同源的服务器上,如果由同源服务器代理至最终需要的服务器,从而实现跨域的目的,例如通过nginx,node中间件等。
2.jsonp的方式
jsonp是一种借助script元素实现的跨域技术,它并没有XMLHttpRequest对象,其能够实现跨域主要得益于script的两个特点:
(1)src属性可以访问任何url资源,并不会收到同源策略限制;
(2)如果访问的资源包含JavaScript代码,其会下载后自动执行
3. CORS方式
跨域资源共享(CORS)该机制可以进行跨域访问控制,从而使跨域数据传输的以安全进行(实现一个跨域的请求方式)
2.3两种攻击方式
XSS:跨站脚本攻击(xss;cross site scripting)是指黑客往html文件中或者dom中注入恶意脚本,从而在用户浏览页面时利用恶意脚本对用户实施攻击的一种手段
产生的影响:XSS攻击的主要影响有:到期cookie信息,监听用户行为,修改dom,在页面生产弹窗广告等
注入的方式:xss注入方式有存贮型xss攻击,反射型xss攻击,基于dom的xss攻击
什么情况容易发生xss攻击:
主要有两个:1.数据从一个不可靠的链接进入到一个web程序,2.没有过滤掉恶意代码的动态内容被发给web用户
如何阻止xss攻击?
阻止xss攻击的方式有三种:1,服务器对输入脚本进行过滤或转码,2.充分利用csp,3.使用httpOnly属性
CSRF
跨域请求伪造(CSRF;Cross-site request forgery) 指的是黑客引诱用户打开黑客的网址,在网址中里用客户的登录状态发起跨站请求。
攻击原理:
攻击的前提条件主要有以下三点:
攻击的方式:
防止CSRF攻击的策略 :充分利用好Cookie的SameSite属性,在服务器端验证请求的来源站点,CSRF Token
三、浏览器安全
HTTP请求报文主要包括:请求行、请求头部以及请求的数据(实体),下面一起看看其组成内容:
请求行包含:
方法字段、URI字段和协议版本
方法字段
GET(请求获取内容);
POST(提交表单);
HEAD(请求资源响应消息报头);
PUT(传输文件);
DELETE(请求删除URI指向的资源);
OPTIONS(查询针对请求URI指定的资源支持的方法);
TRACE(追踪请求经过路径);
CONNECT(要求用隧道协议连接代理)。
3.1.2 请求头部
常见标头有:Connection标头(连接管理)、Host标头(指定请求资源的主机)、Range标头(请求实体的字节范围)、User-Agent标头(包含发出请求的用户信息)、Accept标头(首选的媒体类型)、Accept-Language(首选的自然语言)
3.1.3 请求实体
HTTP请求的body主要用于提交表单场景。实际上,http请求的body是比较自由的,只要浏览器端发送的body服务端认可就可以了。一些常见的body格式是:
application/json
application/x-www-form-urlencoded
multipart/form-data
text/xml
使用html的form标签提交产生的html请求,默认会产生 application/x-www-form-urlencoded 的数据格式,当有文件上传时,则会使用multipart/form-data。
3.2 响应报文
HTTP响应报文分为三个部分:状态行、首部行和响应体.
3.2.1 状态行:
状态行是由版本、状态码和原因语句组成,下面来看看一些常用的状态码
1xx:这一类型的状态码,代表请求已被接受,需要继续处理。这类响应是临时响应,只包含状态行和某些可选的响应头信息,并以空行结束
2xx:这一类型的状态码,代表请求已成功被服务器接收、理解并接受
200---OK/请求已经正常处理完毕;
204---请求处理成功,但没有资源返回;
206---表示客户端进行了范围请求,而服务器成功执行了这部分的GET请求;
3xx:这类状态码代表需要客户端采取进一步的操作才能完成请求。通常,这些状态码用来重定向,后续的请求地址(重定向目标)在本次响应的Location域中指明
301---请求永久重定向 被请求的资源已永久移动到新位置,并且将来任何对此资源的引用都应该使用本响应返回的若干个 URI 之一。如果可能,拥有链接编辑功能的客户端应当自动把请求的地址修改为从服务器反馈回来的地址。
302---请求临时重定向 由于这样的重定向是临时的,客户端应当继续向原有地址发送以后的请求。只有在Cache-Control或Expires中进行了指定的情况下,这个响应才是可缓存的。
303---表示由于请求对应的资源存在着另一个URI,应使用GET方法定向获取请求的资源
304---表示客户端发送附带条件的请求(指采用GET方法的请求报文中包含If-Match,If-Modified-Since,If-None-Match,If-Range,If-Unmodified-Since中任一首部)时,服务端允许请求访问资源,但未满足条件的情况
307---临时重定向,与302含义相同,但是307会遵照浏览器标准,不会从POST变成GET
4xx:这类状态码代表客户端类的错误
400---客户端请求存在语法错误
401---当前请求需要用户验证。
403---服务器已经理解请求,但是拒绝执行它。与401响应不同的是,身份验证并不能提供任何帮助
404---请求失败,请求所希望得到的资源未被在服务器上发现。
405---请求行中指定的请求方法不能被用于请求相应的资源。
5xx:服务器类的错误
500---服务器遇到了一个未曾预料的状况,导致了它无法完成对请求的处理。
501---服务器不支持当前请求所需要的某个功能。当服务器无法识别请求的方法,并且无法支持其对任何资源的请求。
503---由于临时的服务器维护或者过载,服务器当前无法处理请求。
505---服务器不支持,或者拒绝支持在请求中使用的 HTTP 版本。
3.2.2 响应首部:
常见的响应首部有:Date(响应的时间)、Via(报文经过的中间节点)、Last-Modified(上一次修改时间)、Etag(与此实体相关的实体标记)、Connection(连接状态)、Accept-Ranges(服务器可接收的范围类型)、Content-Type(资源类型)
3.2.3 响应体
响应体就是响应的消息体,如果是纯数据就是返回纯数据,如果请求的是HTML页面,那么返回的就是HTML代码,如果是JS就是JS代码等。
HTTP的缺点
1.HTTP通信使用明文(不加密),内容可能会被窃听;
TCP/IP是可能被窃听的网络:按TCP/IP协议族的工作机制,通信内容在所有线路上都有可能遭到窥视。所以需要加密处理防止被窃听,加密的对象如下:
(1)通信的加密
通过和SSL(Secure Socket Layer,安全套接层)或TLS(Transport Layer Security,安全层传输协议)的组合使用,加密HTTP的通信内容。用SSL建立安全通信线路之后,就可以在这条线路上进行HTTP通信了。与SSL组合使用的HTTP称为HTTPS,通过这种方式将整个通信线路加密。
(2)内容的加密
由于HTTP协议中没有加密机制,那么就对HTTP协议传输的内容本身加密。为了做到有效的内容加密,前提是要求客户端和服务器同时具备加密和解密机制。该方式不同于将整个通信线路加密处理,内容仍有被篡改的风险。
2.不验证通信方的身份,因此有可能遭遇伪装;
(1)任何人都可发起请求
HTTP协议不论是谁发送过来的请求都会返回响应,因此不确认通信方,会存在以下隐患:
1)无法确定请求发送至目标的Web服务器是否是按真是意图返回响应的那台服务器,有可能是已伪装的Web服务器;
2)无法确定响应返回到的客户端是否是按照真实意图接收响应的那个客户端,有可能是伪装的客户端;
3)无法确定正在通信的对方是否具备访问权限,因为某些Web服务器上保存着重要的信息,只想发给特定用户通信的权限;
4)无法判断请求是来自何方、出自谁手,即使是无意义的请求也会照单全收,无法阻止海量请求下的Dos攻击(Denial of Service,拒绝服务攻击)。
(2)查明对手的证书
SSL不仅提供加密处理,还使用了一种被称为证书的手段,可用于确定通信方。证书由值得信任的第三方机构颁发,用以证明服务器和客户端是实际存在的。使用证书,以证明通信方就是意料中的服务器,对使用者个人来讲,也减少了个人信息泄露的危险性。另外,客户端持有证书即可完成个人身份的确认,也可用于对Web网站的认证环节。
3.无法证明报文的完整性,所以有可能已遭遇篡改。
在请求或响应送出之后直到对方接收之前的这段时间内,即使请求或响应的内容遭到篡改,也没有办法获悉。在请求或响应的传输途中,遭攻击者拦截并篡改内容的攻击称为中间人攻击(Man-in-the-Middle attack)。仅靠HTTP确保完整性是非常困难的,便有赖于HTTPS来实现。SSL提供认证和加密处理及摘要功能。
HTTPS基础知识点
HTTPS 并非是应用层的一种新协议。只是 HTTP 通信接口部分用SSL(Secure Socket Layer)和TLS(Transport Layer Security) 协议代替而已,简言之就是HTTP 通信加密 证书 完整性保护构成HTTPS,是身披TLS/SSL这层外壳的HTTP。
TLS/SSL功能
TLS/SSL协议使用通信双方的客户证书以及CA根证书,允许客户/服务器应用以一种不能被偷听的方式通信,在通信双方间建立起了一条安全的、可信任的通信通道。
对称加密和非对称加密(公开密钥加密)
(1)对称加密
对称加密指的是加密数据用的密钥,跟解密数据用的密钥是一样的,使用该方法的优缺点是:
1)优点:加密、解密效率通常比较高、速度快。对称性加密通常在消息发送方需要加密大量数据时使用,算法公开、计算量小、加密速度快、加密效率高。
2)缺点:数据发送方、数据接收方需要协商、共享同一把密钥,并确保密钥不泄露给其他人。此外,对于多个有数据交换需求的个体,两两之间需要分配并维护一把密钥,这个带来的成本基本是不可接受的。
(2)非对称加密
非对称加密指的是加密数据用的密钥(公钥),跟解密数据用的密钥(私钥)是不一样的。公钥就是公开的密钥,谁都可以查到;私钥就是非公开的密钥,一般是由网站的管理员持有。公钥与私钥之间有一定联系:简单来说就是,通过公钥加密的数据,只能通过私钥解开;通过私钥加密的数据,只能通过公钥解开。
非对称加密(公开密钥加密)存在的问题
非对称加密其实是存在一些问题需要解决的,主要有以下两个:公钥如何获取、数据传输单向安全。
非对称加密中公钥如何获取
为了获取公钥,需要涉及到两个重要概念:证书、CA(证书颁发机构),其主要用途如下:
(1)证书:可以暂时把它理解为网站的身份证。这个身份证里包含了很多信息,其中就包含了上面提到的公钥。当访问相应网站时,他就会把证书发给浏览器;
(2)CA:用于颁发证书,证书来自于CA(证书颁发机构)。
证书可能存在的问题
(1)证书是伪造的:压根不是CA颁发的
(2)证书被篡改过:比如将XX网站的公钥给替换了
证书如何防伪
数字签名、摘要是证书防伪非常关键的武器。“摘要”就是对传输的内容,通过hash算法计算出一段固定长度的串。然后,在通过CA的私钥对这段摘要进行加密,加密后得到的结果就是“数字签名”(明文 --> hash运算 --> 摘要 --> 私钥加密 --> 数字签名);数字签名只有CA的公钥才能够解密。证书中包含了:颁发证书的机构的名字 (CA)、证书内容本身的数字签名(用CA私钥加密)、证书持有者的公钥、证书签名用到的hash算法等。
(1)对于完全伪造的证书
这种情况对证书进行检查
1)证书颁发的机构是伪造的:浏览器不认识,直接认为是危险证书
2)证书颁发的机构是确实存在的,于是根据CA名,找到对应内置的CA根证书、CA的公钥。用CA的公钥,对伪造的证书的摘要进行解密,发现解不了。认为是危险证书
(2)篡改过的证书
1)检查证书,根据CA名,找到对应的CA根证书,以及CA的公钥。
2)用CA的公钥,对证书的数字签名进行解密,得到对应的证书摘要AA
3)根据证书签名使用的hash算法,计算出当前证书的摘要BB
4)对比AA跟BB,发现不一致--> 判定是危险证书
HTTPS问题
(1)与纯文本相比,加密通信会消耗更多的CPU及内存资源
1)由于HTTPS还需要做服务器、客户端双方加密及解密处理,因此会消耗CPU和内存等硬件资源。
2)和HTTP通信相比,SSL通信部分消耗网络资源,而SSL通信部分,由因为要对通信进行处理,所以时间上又延长了。SSL慢分两种,一种是指通信慢;另一种是指由于大量消耗CPU及内存等资源,导致处理速度变慢。
(2)购买证书需要开销。
HTTPS流程
1.客户端发起HTTPS请求
2.服务端响应,下发证书(公开密钥证书)
3.客户端检查证书,如果证书没问题,那么就生成一个随机值,然后用证书(公钥)对该随机值进行加密。
4.将经过公钥加密的随机值发送到服务端(非对称加密),以后客户端和服务器的通信就可以通过这个随机值进行加密解密了。
5.服务端用私钥解密后,得到了客户端传过来的随机值,然后把内容通过该值进行对称加密。
6.后期的数据传输都是基于该随机值进行加密解密。
浏览器系统安全
查看自身ip以及物理地址
win R cmd 输入 ipconfig/all
微信小程序css样式篇
微信小程序宽度百分百 换算于 750rpx
假设轮播图为宽度为百分百等于750rpx 后设有左右边距为20rxp 此时图片为730rpx导致图片两侧内容被吃掉无法显示
可以用750÷380这个模拟器尺寸 得出1.97
1.97×图片高度145 = 285 得出图片完整显示
这篇好文章是转载于:学新通技术网
- 版权申明: 本站部分内容来自互联网,仅供学习及演示用,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,请提供相关证据及您的身份证明,我们将在收到邮件后48小时内删除。
- 本站站名: 学新通技术网
- 本文地址: /boutique/detail/tanhgbckci
-
photoshop保存的图片太大微信发不了怎么办
PHP中文网 06-15 -
Android 11 保存文件到外部存储,并分享文件
Luke 10-12 -
word里面弄一个表格后上面的标题会跑到下面怎么办
PHP中文网 06-20 -
《学习通》视频自动暂停处理方法
HelloWorld317 07-05 -
photoshop扩展功能面板显示灰色怎么办
PHP中文网 06-14 -
微信公众号没有声音提示怎么办
PHP中文网 03-31 -
excel下划线不显示怎么办
PHP中文网 06-23 -
怎样阻止微信小程序自动打开
PHP中文网 06-13 -
excel打印预览压线压字怎么办
PHP中文网 06-22 -
TikTok加速器哪个好免费的TK加速器推荐
TK小达人 10-01
